Panoramica
Il Rilevamento dell’Attività Vocale (VAD) e i controlli di Turn Detection consentono ai tuoi agenti AI di riconoscere quando gli utenti stanno parlando, rilevare quando hanno terminato il loro turno e gestire le interruzioni in modo naturale. Queste impostazioni sono fondamentali per creare conversazioni fluide e simili a quelle umane che risultano reattive senza interrompere gli utenti a metà frase. VAD e turn detection lavorano insieme per determinare quando ascoltare, quando rispondere e come gestire le interruzioni - trasformando il riconoscimento vocale di base in interazioni conversazionali naturali.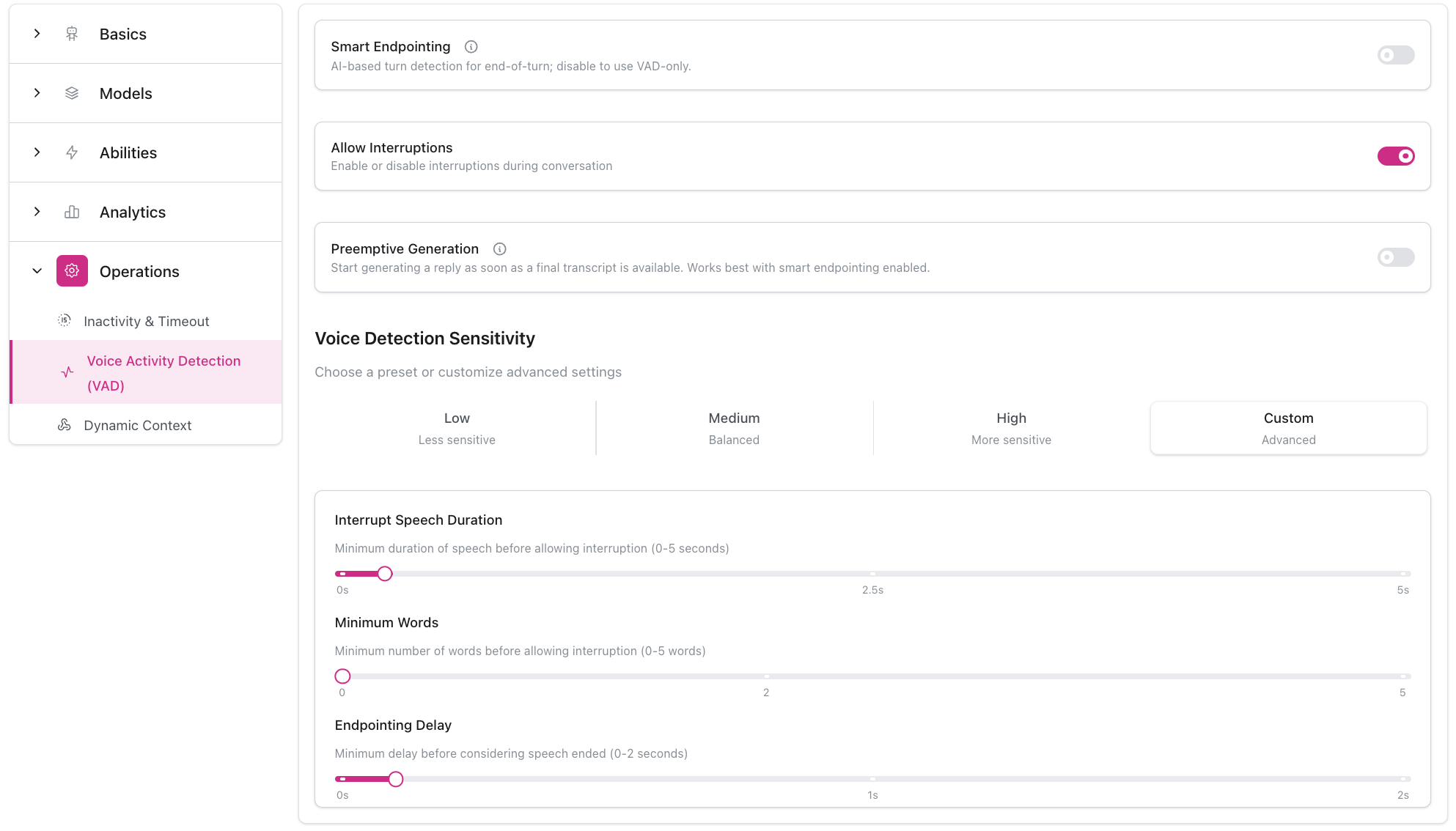
Applicazione Universale: Le impostazioni VAD e turn detection si applicano a tutti i tipi di conversazione, comprese le chiamate telefoniche (SIP/PSTN) e le conversazioni basate sul web.La configurazione è disponibile in Impostazioni Agente → Operations → Voice Activity Detection (VAD). Le impostazioni includono preset di sensibilità, smart endpointing, gestione delle interruzioni e parametri di ottimizzazione avanzati.
Cos’è il Rilevamento dell’Attività Vocale?
Comprendere la Tecnologia VAD
Il Rilevamento dell’Attività Vocale (VAD) è la tecnologia che determina quando qualcuno sta parlando rispetto a quando c’è silenzio o rumore di fondo. È la base per sapere quando ascoltare e quando un utente ha finito di parlare. Componenti chiave:- Rilevamento del Parlato: Identifica quando inizia l’attività vocale
- Rilevamento del Silenzio: Riconosce quando il parlato è terminato
- Filtraggio del Rumore: Distingue il parlato dai suoni di fondo
Cos’è il Turn Detection?
Il turn detection (chiamato anche “endpointing”) determina quando un parlante ha finito il proprio turno conversazionale ed è il momento per l’agente di rispondere. Questo è più sofisticato del semplice rilevamento del silenzio, poiché tiene conto delle pause naturali, del tempo di riflessione e del contesto conversazionale.Smart Endpointing
Turn Detection Basato su AI
Lo Smart Endpointing utilizza un modello AI per rilevare la fine del turno in modo più accurato rispetto al solo VAD di base. Questa funzionalità avanzata aiuta a prevenire l’interruzione degli utenti durante pause naturali mantenendo comunque un flusso di conversazione reattivo. Vantaggi:- Riduce le interruzioni false durante pause naturali
- Migliora la gestione del barge-in quando gli utenti interrompono
- Gestisce meglio le frasi con più clausole
- Tiene conto del contesto conversazionale
Toggle Smart Endpointing
Abilita o disabilita il turn detection basato su AI. Quando disabilitato, il sistema utilizza il rilevamento solo VAD con tempi di risposta più rapidi.
Preset di Sensibilità
Opzioni di Configurazione Rapida
Scegli tra livelli di sensibilità preconfigurati che bilanciano reattività e accuratezza. Ogni preset regola automaticamente più parametri per prestazioni ottimali in scenari comuni.Sensibilità Bassa
Sensibilità Bassa
Meno sensibile, meno interruzioniIdeale per:
- Ambienti con rumore di fondo
- Utenti che parlano con lunghe pause
- Conversazioni formali che richiedono pazienza
Sensibilità Media (Raccomandata)
Sensibilità Media (Raccomandata)
Sensibilità bilanciataIdeale per:
- Conversazioni generiche
- Ambienti misti
- La maggior parte dei casi d’uso aziendali
Sensibilità Alta
Sensibilità Alta
Più sensibile, risposte più rapideIdeale per:
- Conversazioni a ritmo veloce
- Ambienti audio puliti
- Interazioni sensibili al tempo
Impostazioni Avanzate
Configurazione Personalizzata
Per un controllo preciso, passa alla modalità “Custom” per accedere a parametri avanzati. Queste impostazioni consentono un’ottimizzazione precisa per casi d’uso o ambienti specifici.Gestione delle Interruzioni
Consenti Interruzioni
Consenti Interruzioni
Interruttore principale per la gestione delle interruzioniQuando abilitato, gli utenti possono interrompere l’agente mentre sta parlando. Quando disabilitato, l’agente completerà la sua risposta prima di accettare nuovo input.Casi d’uso:
- Abilitato: Conversazioni naturali, supporto clienti, dialoghi interattivi
- Disabilitato: Annunci importanti, disclaimer legali, script strutturati
Durata Parlato Interruzione
Durata Parlato Interruzione
Durata minima del parlato prima di consentire l’interruzione (0-5 secondi)Controlla quanto tempo un utente deve parlare prima che l’agente lo riconosca come tentativo di interruzione.
- Valori più bassi (0,2-0,5s): Più reattivi, ma possono attivarsi su brevi interiezioni
- Valori più alti (1,0-2,0s): Più stabili, richiedono parlato sostenuto per interrompere
Parole Minime
Parole Minime
Conteggio minimo di parole prima di consentire l’interruzione (0-5 parole)Richiede che l’utente pronunci un certo numero di parole prima di riconoscere un’interruzione.
- 0 parole: Interrompi al rilevamento di qualsiasi parlato
- 1-2 parole: Bilancio tra reattività e stabilità
- 3-5 parole: Richiedi input sostanziale prima di interrompere
Ritardo Endpointing
Ritardo Endpointing
Ritardo minimo di silenzio prima di considerare terminato il parlato (0-2 secondi)Quanto tempo attendere in silenzio prima di determinare che l’utente ha finito di parlare.
- Valori più bassi (0,2-0,5s): Risposte più rapide, ma possono interrompere pause riflessive
- Valori più alti (1,0-2,0s): Più pazienti, consentono pause naturali e tempo di riflessione
Soglia VAD
Soglia VAD
Sensibilità del rilevamento vocale (0,0 - 1,0)Controlla quanto il sistema è sensibile nel rilevare il parlato rispetto al silenzio o al rumore.
- Valori più bassi (0,1-0,3): Meno sensibile, richiede parlato più chiaro
- Valori medi (0,4-0,6): Bilanciato per la maggior parte degli ambienti
- Valori più alti (0,7-1,0): Più sensibile, rileva parlato più silenzioso
Prefix Padding
Prefix Padding
Buffer audio prima del rilevamento del parlato (0-500ms)Quantità di audio da includere prima che venga rilevato il parlato. Questo aiuta a prevenire il taglio dell’inizio di parole o frasi.
- Valori più bassi (0-50ms): Buffer minimo, rischio di taglio inizio parlato
- Valori medi (100-200ms): Buon equilibrio per la maggior parte dei casi
- Valori più alti (300-500ms): Massima preservazione dell’inizio del parlato
Durata Silenzio
Durata Silenzio
Soglia di silenzio prima di terminare il turno (0-2000ms)Quanto tempo attendere in silenzio prima di considerare terminato il parlato dell’utente.
- Valori più bassi (100-300ms): Risposte rapide, ma possono interrompere pause
- Valori medi (400-800ms): Bilanciato per conversazione naturale
- Valori più alti (1000-2000ms): Molto pazienti, consentono lunghe pause riflessive
Generazione Preventiva
Generazione Preventiva
Inizia a generare risposte prima che il turn detection sia completatoQuando abilitato, l’agente inizia a generare una risposta non appena è disponibile una trascrizione finale, anche prima di confermare la fine del turno. Questo può ridurre la latenza percepita ma potrebbe occasionalmente generare risposte che vengono annullate se l’utente continua a parlare.Migliori pratiche:
- Funziona meglio con smart endpointing abilitato
- Ideale per conversazioni sensibili al tempo
- Potrebbe aumentare i costi API a causa di generazioni annullate
Best Practice di Configurazione
Scegliere le Impostazioni Giuste
Inizia con i Preset
Inizia con il preset di sensibilità Media per la maggior parte dei casi d’uso. Testa nel tuo ambiente reale prima di personalizzare.
Testa con Utenti Reali
Diversi accenti, modelli di parlato e velocità possono richiedere impostazioni diverse. Testa con utenti rappresentativi.
Considera Smart Endpointing
Abilita smart endpointing solo se l’agente interrompe gli utenti a metà turno troppo spesso e altre impostazioni (ritardo endpointing, sensibilità) non possono risolverlo. Ricorda che aggiunge latenza.
Regola in Base all'Ambiente
Gli ambienti rumorosi beneficiano di sensibilità più bassa. Gli ambienti silenziosi possono usare sensibilità più alta per interazioni più reattive.
Scenari Comuni
Guida alla Risoluzione dei Problemi
L'agente interrompe gli utenti a metà frase
L'agente interrompe gli utenti a metà frase
Sintomi: L’agente inizia a rispondere prima che gli utenti finiscano di parlareSoluzioni:
- Aumenta ritardo endpointing o durata silenzio
- Passa a un preset di sensibilità più bassa
- Se usi impostazioni personalizzate, aumenta il requisito di parole minime
- Considera l’abilitazione di smart endpointing come ultima risorsa (aggiunge latenza)
L'agente risponde troppo lentamente
L'agente risponde troppo lentamente
Sintomi: Ritardo evidente tra la fine dell’utente e la risposta dell’agenteSoluzioni:
- Diminuisci ritardo endpointing o durata silenzio
- Passa a un preset di sensibilità più alta
- Disabilita smart endpointing se abilitato (riduce latenza)
- Abilita generazione preventiva
L'agente non riconosce le interruzioni
L'agente non riconosce le interruzioni
Sintomi: Gli utenti non possono interrompere l’agente mentre parlaSoluzioni:
- Assicurati che “Consenti Interruzioni” sia abilitato
- Diminuisci durata parlato interruzione
- Riduci requisito parole minime
- Passa a preset di sensibilità più alta
Attivazioni false dal rumore di fondo
Attivazioni false dal rumore di fondo
Sintomi: L’agente risponde a suoni o rumori di fondoSoluzioni:
- Passa a preset di sensibilità più bassa
- Diminuisci soglia VAD
- Aumenta requisito parole minime
- Aumenta durata parlato interruzione
Parlato perso da utenti che parlano piano
Parlato perso da utenti che parlano piano
Sintomi: L’agente non rileva quando utenti silenziosi stanno parlandoSoluzioni:
- Passa a preset di sensibilità più alta
- Aumenta soglia VAD
- Diminuisci durata parlato interruzione
- Verifica qualità microfono/input audio
Funzionalità Correlate
Impostazioni Vocali
Configura velocità vocale, tono e altri parametri TTS
Suono Ambientale
Aggiungi audio di sottofondo per conversazioni più naturali
Pronunce Personalizzate
Assicura la corretta pronuncia di nomi e termini tecnici
Controlli DTMF
Configura l’interazione con la tastiera telefonica per la navigazione IVR